背景
最近在实习公司里负责一个性能比较敏感的服务(延迟P99在10ms),优化了之前出现的一些问题。这个服务之前在晚高峰期间的qps达到45w,接入了几个新功能后涨到50w+,线上是部署了约500个8核8G的实例,因此平均下来每个实例的qps在900~1100之间。
出现的问题如下:
-
高负载下内存占用率极高,保持在7G左右,这样一抖动很容易OOM,现实是晚高峰期间都会有十几次OOM报警。
-
延迟周期性抖动,用较高qps压测显示每两分钟延迟升高,CPU占用率抖动达到90%以上。在晚高峰下的表现为上游调用失败率(timeout)涨到1%左右。
内存占用
对于第一个问题,我仔细阅读了该服务的代码,发现在每次请求的处理中需要多次使用哈希表来处理数据,而且逻辑上这个哈希表无法优化掉。原先的作者是如此构造这个哈希表的:在kv数量小于100的时候使用16个shard的二维slice来模拟,在数量大于100后转而把数据放进map[int]int中。最后使用Golang标准库的sync.Pool来复用这些map。
这么做粗看没什么问题,实际上问题大了,可能是之前服务的qps不高导致问题没有显现出来。通常我们使用sync.Pool是用于对象复用,也就是避免许多对象的重复内存分配,在对象用完以后把它Put到临时对象池里,尽量延迟它的回收,在下次申请同样的对象时从池子里拿。当然sync.Pool不是传统意义上的对象池,如果一些对象在一段时间内没有被重用,还是会被gc回收的。
但是在这里,sync.Pool回收的对象是数组和map,在我们放进去的时候自然是需要把数组每一个shard给清空的(这样才能在下一次的时候方便使用),map也是如此。那么此时被回收的对象可以理解为空的map和slice,真正的数据已经失引用了,等待gc回收。
go的内存回收有GOGC变量控制,默认为100,即堆内存达到上次回收后内存的两倍时触发自动gc,此外如果两分钟未触发过gc,则会强制触发。这个服务内存占用本身比较高,因此默认情况下很少会主动触发gc,一般都是2min一次强制gc。在这2min内这些失引用的对象就一直占用着本就捉襟见肘的内存,自然会导致内存占用极高,而且会随qps升高而升高。
于是这里我做的优化是用sync.Pool复用更基础的对象——哈希表的结点,在之前我们复用哈希表是无效的,因为哈希表清空后,其内部数据失引用。因此我自己实现一个简易版本的链式哈希表,这样其内部的结点可以手动管理,用于对象复用,定义如下:
type Node struct {
key int
val int
next *Node
}
var NodePool *sync.Pool = &sync.Pool {
New: func() interface{} {
return &Node{}
},
}
链式哈希表的实现就很简单了(不会的话自行google),在这里我使用固定的entry大小,不考虑哈希表的扩容(因为场景很单一,kv数量不会很多),在申请结点和free结点的时候从NodePool中取即可。经过这么优化,服务的内存占用骤降,从~7G一下子降到了4~5G,OOM的问题就完全解决了。
CPU性能
实际上这么实现后一段时间服务都没什么问题,无论是从内存还是延迟都有提升,直到今年五一上了一个新功能后,这个服务的qps涨了近30%,于是放假第一天晚上高峰期qps一下上到50w,错误率就涨到了2%,于是假期结束后又开始追查问题了。
经过压测可以观察到延迟的抖动以基本固定的2min间隔发生,那么基本上可以确定是gc导致的。回顾一下Golang的gc机制,可以参考这篇文章:
-
清理终止阶段;
暂停程序,所有的处理器在这时会进入安全点(Safe point);
如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;
-
标记阶段;
将状态切换至 _GCmark、开启写屏障、用户程序协助(Mutator Assiste)并将根对象入队;
恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段;
-
标记终止阶段;
暂停程序、将状态切换至 _GCmarktermination 并关闭辅助标记的用户程序;
清理处理器上的线程缓存;
-
清理阶段;
将状态切换至 _GCoff 开始清理阶段,初始化清理状态并关闭写屏障;
恢复用户程序,所有新创建的对象会标记成白色;
后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理;
实际上如果你开启gc trace(程序启动时设置GODEBUG=gctrace=1),观察控制台输出的gc耗时,会发现golang暂停程序的时间是极其短的,不超过1ms。其主要耗时在于并发标记阶段需要对所有内存中的对象扫描一遍,确定将要回收的对象。这一过程会在每个逻辑处理器上绑定一个go routine来并发执行,此时CPU使用率会有显著的上升。显然,这一过程的消耗与对象的总数量强相关。
前面提到,我使用sync.Pool来复用了大量的链表结点Node用于构造哈希表,可以想象同一时刻内存中保持了数十万个Node,而sync.Pool仅仅能够规避掉内存反复分配和释放的开销,以及无效对象的堆积产生的内存开销,并不能缓解gc时对内存对象扫描的压力。
这个问题的解法是实现更加gc友好的对象池,总的来说有两种方法:
-
通过用cgo调用malloc申请对象的内存,然后以指针来使用,由于malloc申请到的内存不会被gc追踪,自然就无gc开销。
-
服务启动之初直接申请一块大数组,后续对象直接从数组中取用(按下标获取),可以使用一个used数组来记录使用情况(占用时置1,归还时置0)。这样由于大数组是一个整体,扫描时等同于一个对象,也无压力。
在这里我使用的是第二种方法,因为第一种的话还要考虑对象的存放(如果申请的byte数组,然后用unsafe方式使用的话,效果也等同于第二种)。同时第二种也不需要unsafe,更优雅一点。
此时还有未解决的问题是如何支持高并发度的对象存取,每次取对象需要从一个大数组中选择一个未使用的下标,然后把used置1,每次放回对象的时候需要把对应下标的used置0。因此Node结构需要增加一个域表示其在数组中的偏移(下标):
type Node struct {
key int
val int
idx int
next *Node
}
var nodes []Node
高并发的情况下如何选择下标呢?可以简单的使用随机数减少冲突,但是这里有一个问题,如果每次申请Node时都计算一个随机数的话,使用pprof查看耗时,计算随机数也会产生很大的overhead,因为申请Node是很频繁的操作。在此我做了一个优化——同一个哈希表仅在第一次申请Node时使用随机偏移,后续使用上一次的下一位,以此类推,直到产生冲突。
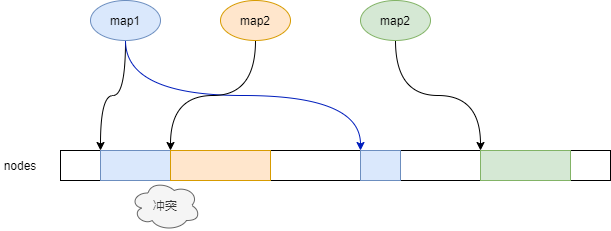
如图,map2和map3的Node申请在连续的空间上,而map1使用的连续空间与map2产生冲突,于是才重新生成一个随机的位置。这么做很好地降低了计算随机数的overhead。
代码非常之简单,仅供参考,Get传入的idx是上一个node的偏移量,我们使用CAS实现轻量级的并发控制:
type NodePool struct {
nodes []node
used []int32
size int
}
func (c *NodePool) Put(n *node) {
n.next = nil
if n.idx != -1 {
c.used[n.idx] = 0
}
}
func (c *NodePool) Get(key int, val uint16, idx int) *node {
idx++
if idx == 0 {
idx = frand.Intn(c.size)
}
for i := 0; i < 10; i++ {
if atomic.CompareAndSwapInt32(&c.used[idx], 0, 1) {
c.nodes[idx].key = key
c.nodes[idx].val = val
return &c.nodes[idx]
}
idx = frand.Intn(c.size)
}
return &node{
key: key,
val: val,
idx: -1,
next: nil,
}
}
注意到重试的次数是有限的,当数组占用率很高的时候,我们重新选择位置的次数不超过10次,否则就直接给一个自由的node应急使用,用idx=-1来标记即可。在这个服务里我设置的数组长度为2^21,足够大,因此很少出现重试的情况。
经过这么优化后,再次对服务进行压测,发现CPU的占用率较之前显著下降,基本看不出gc造成的延时波动(或者说极小),上线观察下来晚高峰下延迟也不再波动了。问题解决!
一个值得注意的点:如果你使用指针数组[]*node来存储所有的node,是没有效果的,因为此时相当于一个数组引用了数百万个小对象,gc依然需要根据指针进行扫描。
总结
其实都是很小的问题,但是在高并发量高性能要求的场景下,就会暴露出来,对于golang这种带gc的语言,总结下来就是尽量做到对象内存的复用,对于需要大量小对象的场景考虑合并成大对象,控制内存中的对象总量,以缓解gc压力。