本文分析reactor模式,这是广泛应用于许多网络框架下的异步IO模式。
I/O
I/O通常是现今计算机运行中最慢的操作,无论是读取文件还是网络传输。读取磁盘上的文件通常花费的时间在毫秒级,而一次内存的读取花费的时间在纳秒级。同样的,网络传输/磁盘读取的速度通常为以MB/s为单位,而内存存取速率通常以GB/s为单位。对于CPU来说,IO操作并不昂贵,但它通常会导致操作的延时。
Blocking I/O
在传统的阻塞式IO编程中,一次包含I/O请求的函数调用会阻塞整个线程,直到IO操作完成,这通常导致一个函数的操作时间过长。在这种模式下,显然单个线程无法同时处理多个网络请求。因此,在几十年前的服务器编程中,传统的方式是为每个到来的网络连接开启一个线程(或者从线程池中取一个空闲线程),这样单个请求的读取过程即使阻塞了一个线程,也不会影响其他请求的处理。
在这种模式下,任何有关IO的操作都会使得线程阻塞,这些操作包括读取socket,发送socket,读取文件,写文件,数据库请求等等。也就是说,在一次请求处理中,线程可能会阻塞很多次。在这期间实际上CPU是空闲的,而如果线程过多,线程的调度会加重CPU的负担——这是额外的消耗,特别是对于Linux这类重线程的操作系统,每个线程都耗费不小的内存空间,并带来上下文切换的开销。
Non-blocking I/O
除了阻塞式IO,大多数现代操作系统支持另一种获取资源的方式——非阻塞式I/O。在这种模式下,涉及IO的系统调用总是立即返回,而不等待数据读写完成。如果在调用时数据未就绪,则调用会返回一个预定义的值,表示当前数据未准备好。
例如,在Unix系统中,fcntl()函数可以用来控制一个已有的文件操作符,将其的读写模式改变为非阻塞(用O_NONBLOCK标志位)。一旦文件操作在非阻塞模式下,如果该文件还没有数据可读,则读操作会返回EAGAIN。
最基本的使用非阻塞IO的编程范式是在一个循环里不断地轮询相应接口,直到有数据返回——这被称为忙等待。下面的伪代码展示了这一逻辑:
resources = [socketA, socketB, pipeA];
while(!resources.isEmpty()) {
for(i = 0; i < resources.length; i++) {
resource = resources[i];
//try to read
var data = resource.read();
if(data === NO_DATA_AVAILABLE)
//there is no data to read at the moment
continue;
if(data === RESOURCE_CLOSED)
//the resource was closed, remove it from the list
resources.remove(i);
else
//some data was received, process it
consumeData(data);
}
}
你可以看到,这么简单的代码已经可以在单线程里面处理多个I/O资源的读写了,但还不够高效。事实上,在上面的例子中,忙等待会浪费很多CPU时间——因为大多数时候资源都是不可用的。我们希望等到资源可用的时候能够自动通知线程,而不是线程一直循环着浪费CPU资源。
Event demultiplexing
忙等待不是处理非阻塞IO的理想策略,幸运的是,大多是现代操作系统提供了原生高效的非阻塞I/O的API,这种接口称为synchronous event demultiplexer,或者event notification interface。这种机制下,多个资源会被置于监视之下,一旦有资源可用,则添加对应的event到一个队列下,如果这些资源均不可用,接口会阻塞。
下面的伪代码解释了这一机制:
socketA, pipeB;
watchedList.add(socketA, FOR_READ); //[1]
watchedList.add(pipeB, FOR_READ);
while(events = demultiplexer.watch(watchedList)) { //[2]
//event loop
foreach(event in events) { //[3]
//This read will never block and will always return data
data = event.resource.read();
if(data === RESOURCE_CLOSED)
//the resource was closed, remove it from the watched list
demultiplexer.unwatch(event.resource);
else
//some actual data was received, process it
consumeData(data);
}
}
只要有资源是可读的,上面的watch函数就会返回,一旦无资源可读,就会阻塞。在循环中,我们遍历可读的事件,此时read函数将会立即返回数据(因为数据已经准备好了),之后就是我们自己的业务逻辑。这就是事件循环(event loop)。
现在我们可以很从容地从忙等待中解放出来了,因为在数据没有就绪时,线程是阻塞的,不会占用CPU资源,当线程被唤醒时,就代表着有数据就绪,这意味着在循环中,所有的时间都用在关键逻辑处理上,而非浪费时间在IO上。业务逻辑计算通常是迅速的——除非是非常复杂的算法,否则至少比IO快很多,因此单线程并不会影响我们并发处理多个IO事件。
Reactor Pattern
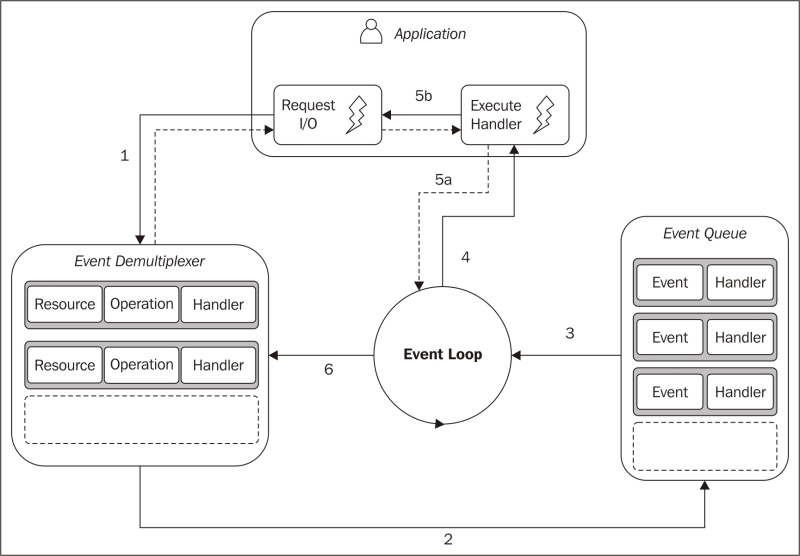
reactor模式是上一节的算法进一步优化的结果。其主要思想是让每一个I/O事件对应一个handler。在event loop中一旦该事件被触发,就调用对应的handler(通常以回调函数的形式定义)进行处理。下图阐释了这一过程:
-
应用把接收到的网络请求提交到event demultiplexer,同时定义对应的handler函数。这一过程是立即返回的。
-
当一系列I/O操作完成后,事件被push到事件队列。
-
事件循环处理到达的事件。
-
每个事件都会调用对应的handler进行处理。
-
handler函数一旦执行完成,就会把控制权返回事件循环。在handler中,例如web服务器,通常会在处理完成后返回一些数据给客户端,这也是新的I/O事件,需要添加到event demultiplexer(5b),然后才返回(5a)。
-
当事件队列处理完为空后,单次循环结束。
Higher Abstraction
每个操作系统都实现了自己的Event Demultiplexer,在Linux上为epoll,Mac OS X上为kqueue,Windows上为I/O Completion Port API(IOCP)。除此之外,对于不同类型的资源,其I/O操作的细节不同。例如,在Unix中,普通的文件是不支持非阻塞读写的,因此为了模拟非阻塞的接口行为,我们只能够在事件循环之外开额外的线程去进行读写。所有这些细节意味着需要更高层级的抽象,封装操作系统底层的API。Node.js团队写了一个C语言库libuv,作为Node.js的底层I/O引擎,使得其能够跨多平台支持非阻塞IO。
除了对底层系统调用进行封装,libuv还实现了reactor模式,提供了创建事件循环,管理事件队列的API。除此之外,还有知名的libevent,muduo之类的网络库都可一用。